Abstraction and instances in graph programming
Antimony's graph model is insufficiently powerful and/or elegant.
This blog post contains a half-baked set of ideas about more powerful and/or elegant systems for reactive hierarchical graph-based programming.
Reactive means that the system automatically propagates changes; if you adjust a circle's radius from 1 to 2, it should re-run any actions that depend on that value (like rendering the circle, changing its UI, recalculating area).
Hierarchical means that graphs can be stored within graphs. See the Graphene writeup for more on this notion.
Let's start at the beginning. When designing in Antimony, users build up models from a library of standard shapes.
This library is mostly written by me and lives in a file tree that's shipped with the application.
Nodes in the library are defined as Python scripts;
instantiating a node means creating a new ScriptNode object
whose text is that particular script.
There are several downsides to this implementation, stemming from the fact that nodes are added by value, rather than by reference.
If I modify the canonical "circle" node in the library (e.g. to add a better UI), this change applies to any circles added after the edits, but existing circles are stuck in the past.
Relatedly, nodes doesn't play by the same reactive rules as the rest of the system. In general, editing a value causes changes to cascade through the graph, but library nodes aren't aware when their definitions change.
On the surface, this library system looks like a set of function definitions, but the implementation is closer to copy-and-pasting the function's body over and over again into the graph.
I've been mulling over a better way,
something that feels more like function calls rather than copy-and-pasting.
I'd like a system which has a single, canonical implementation of a particular
node, and some number of instances of that implementation. Canonical definitions
can use the input / output system of Graphene
to define their interfaces.
In our function metaphor, the canonical implementation is the function; instances are calls to that function. (Alternatively, think of this as object-oriented graph programming.)
Tracking values becomes trickier in this system, because the canonical implementation can have many different values depending on its inputs.
You end up with something like this, where implementations store values keyed by instance:

This gets even more complicated when you allow recursion. If you put instances within instances, then values end up keyed according to the path they took from the root of the graph.
Still, I think there's something interesting here.
The biggest difference between how I use Antimony and how other people use Antimony is in node definition.
My designs tend to put very high-level chunks into nodes. When I was designing gears for the Formlabs Rube Goldberg machine, the design looked like this:
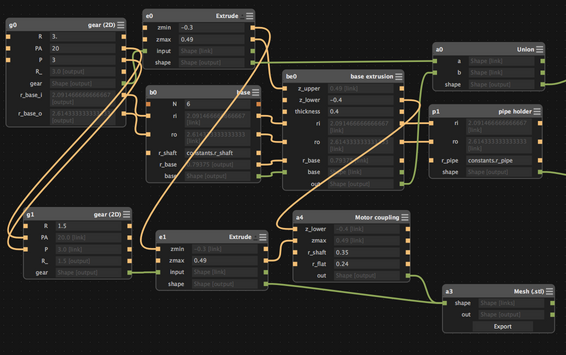
Look at the names of these nodes, things like:
Gear (2D)Base extrusionMotor coupling
There are a few basic primitives (Extrude, Union, etc), but most of the
nodes are fully custom high-level pieces of the design.
When others use Antimony, they tend to build huge graphs of primitive nodes:
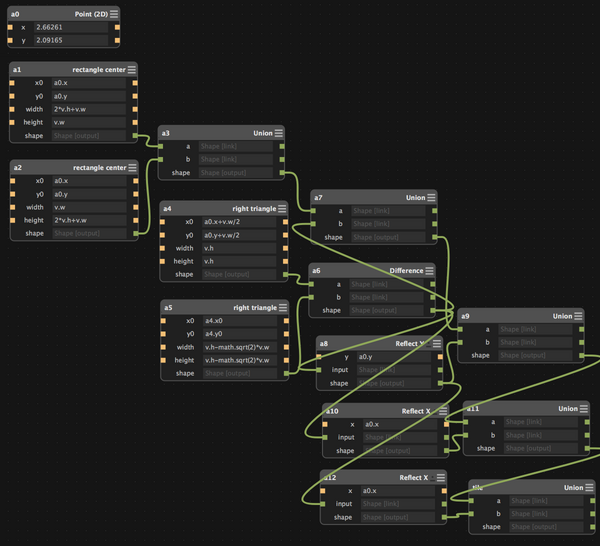
I'd like to make it easier for users to build their own "standard library", with hierarchy and well-defined inputs and outputs, instead of relying on my low-level shapes in a spaghetti graph.
This kind of instance-based representation seems like a step in the right direction.