The Solid-State Register Allocator
I recently found myself needing a very fast register allocator for very simple code. There's a huge amount of academic research on the subject, dating back decades, and just as many published implementations; my specific implementation – while not fundamentally novel – landed in an interesting-enough part of configuration space that it seemed worth writing up.
The system has one big limitation: it only works on straight-line code, without any jumps or branches. On the upside, it has a handful of desirable properties:
- About 100× faster than Clang, and 300× faster than GCC.
- Runs in a single pass over the input code
- Uses one weird trick to avoid calculating liveness ranges
(compiler writers hate him!) - Is almost free of allocation at runtime
My specific implementation of register allocation is written in Rust with very few moving parts, so I've nicknamed it the "solid-state register allocator" (or "SSRA" for short).
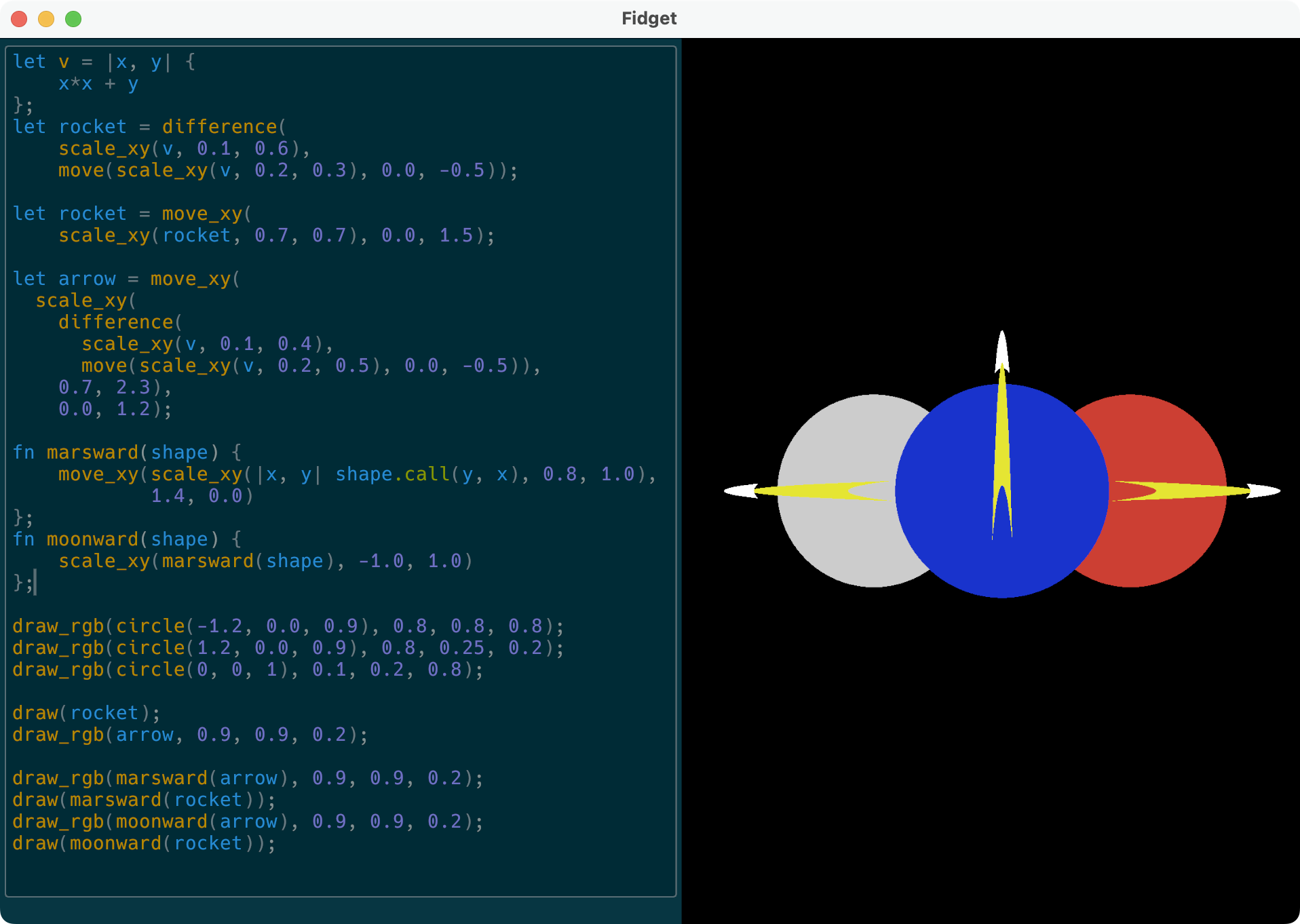
Before we get started, you can take a peek at the finished system with this demo, configured for a fictional machine with only two registers. Edit the text on the left; it's interactive!
What is register allocation?
Let's start at the beginning.
Register allocation is a step in compilation where we go from abstract variables (infinite in supply) to physical machine registers (sadly non-infinite). In my case, I'm working with straight-line code (i.e. without any jumps or branches) in single static assignment form.
Imagine a toy language with only two operations:
FOO, which takes two argumentsBAR, taking no arguments
A simple chunk of code looks something like this:
$0 = BAR()
$1 = BAR()
$2 = FOO($0, $1)
$3 = FOO($2, $1)
Incoming variables are prefixed with the dollar sign $; SSA form means that
operations are only allowed to use variables that have already been defined and
cannot write an existing variable.
Now, let's say we're working on a machine with two physical registers: r0 and
r1.
Just by eyeballing it, the code above could be compiled to
r0 = BAR()
r1 = BAR()
r0 = FOO(r0, r1)
r0 = FOO(r0, r1)
Unfortunately, it's not always that easy. Let's add one more operation:
$0 = BAR()
$1 = BAR()
$2 = FOO($0, $1)
$3 = FOO($2, $1)
$4 = FOO($0, $3)
Intuitively, $0 now needs to live longer; we can no longer overwrite it with
the first FOO operation. Instead, we need to use LOAD and STORE operations
to "spill" it into memory:
r0 = BAR()
r1 = BAR()
STORE(r0, mem + 0)
r0 = FOO(r0, r1)
r0 = FOO(r0, r1)
r1 = LOAD(mem + 0)
r0 = FOO(r0, r1)
Our new program uses both registers r0 and r1, and one word of memory
(indicated as mem + 0). $0 is moved from r0 into memory before r0 is
overwritten, then moved back in time for the final FOO operation.
Liveness ranges
When doing register allocation, we'll often talk about "liveness" or "live ranges" of variables. The live range of a variable is simply the time between when it's first defined and when it's used for the last time.
Here's what that looks like for our previous program:
$0 $1 $2 $3 $4
$0 = BAR() ↑
$1 = BAR() | ↑
$2 = FOO($0, $1) | | ↑
$3 = FOO($2, $1) | ↓ ↓ ↑
$4 = FOO($0, $3) ↓ ↓ ↑
↓
Interestingly, this gives us an intuition for why we can't fit the program into two registers: on the third operation, we have three live values.
In conventional linear scan allocation (PDF), these liveness ranges are critical! Here's the pseudocode from that paper:

You don't need to follow the whole thing, but note how much effort goes into bookkeeping of live ranges:
- It assumes that we already know live ranges; this requires a full pass through the code beforehand.
- We need to keep a set of intervals sorted by increasing end point, and add / remove items from that set; this suggests a non-trivial data structure.
The One Weird Trick
The "one weird trick" to avoid all this bookkeeping is simple:
Do register allocation in reverse.
You may ask, "How does that help?"
When walking through the code in reverse, you get liveness ranges for free, without needing an extra pass:
- The range begins (ends) when a variable is first (last) used as an input
- The range ends (begins) when a variable is written as an output
(Read the parenthesized words to get the "forward" perspective)
It turns out that this isn't a new idea; Mike Pall – author of LuaJIT – disclosed this trick back in 2009, and I suspect the literature trail goes even further back. Here's a good blog post summarizing how LuaJIT uses this strategy. If you'd like to learn more about their implementation, see this IP disclosure or their source code.
A worked example
Register allocation in reverse is extremely counterintuitive. For example, when we reach an operation, we must already know the location of its output (which is either a register or memory location).
This means that we start by assigning the final output variable to a register,
typically r0 (for simplicity).
# $0 = BAR()
# $1 = BAR()
# $2 = FOO($0, $1)
# $3 = FOO($2, $1)
# $4 = FOO($0, $3)
<- You are here; r0 = $4
Let's proceed through our list of operations, and see what we encounter:
# $0 = BAR()
# $1 = BAR()
# $2 = FOO($0, $1)
# $3 = FOO($2, $1)
$4 = FOO($0, $3) <- r0 = $4
At this point, neither input is assigned. Remember that the live span of a
variable ends when it's written to (thinking about the tape in reverse);
this means that we can reuse r0 immediately, remapping it from $4 to $0:
# $0 = BAR()
# $1 = BAR()
# $2 = FOO($0, $1)
# $3 = FOO($2, $1)
r0 = FOO(r0, r1) <- r0 = $0, r1 = $3
Okay, let's keep going:
# $0 = BAR()
# $1 = BAR()
# $2 = FOO($0, $1)
$3 = FOO($2, $1) <- r0 = $0, r1 = $3
r0 = FOO(r0, r1)
Now, we are at an impasse. We can reuse r1 as $3 goes out of scope, but
cannot yet reuse r0, since $0 is still alive. After partially allocating
this instruction, we're stuck here:
# $0 = BAR()
# $1 = BAR()
# $2 = FOO($0, $1)
r1 = FOO(r1, $1) <- r0 = $0, r1 = $2
r0 = FOO(r0, r1)
We must now evict r0 to make space for $1. This takes the form of a
LOAD operation after the operation of interest; we'll move it to mem + 0
# $0 = BAR()
# $1 = BAR()
# $2 = FOO($0, $1)
r1 = FOO(r1, r0) <- r0 = $1, r1 = $2, mem + 0 = $0
LOAD(r0, mem + 0) <- this is added!
r0 = FOO(r0, r1)
Think through how this works for a moment: from the forward perspective, r0
was bound to $0 after the target operation, so the LOAD operation recovers
this binding during forward execution.
Continuing up, we run into a new issue: we're now trying to do an operation on a variable from memory, instead of a register!
# $0 = BAR()
# $1 = BAR()
r1 = FOO($0, r0) <- r0 = $1, mem + 0 = $0
r1 = FOO(r1, r0)
LOAD(r0, mem + 0)
r0 = FOO(r0, r1)
At this point, we know that r1 is newly available. To use it, we add a
STORE operation before the target, moving the variable from r1 into
memory (when looking at the program from a forward perspective):
# $0 = BAR()
# $1 = BAR()
STORE(r1, mem + 0) <- r0 = $1, r1 = $0
r1 = FOO(r1, r0)
r1 = FOO(r1, r0)
LOAD(r0, mem + 0)
r0 = FOO(r0, r1)
The remaining two lines are easy, because their outputs are already in registers:
r1 = BAR()
r0 = BAR()
STORE(r1, mem + 0)
r1 = FOO(r1, r0)
r1 = FOO(r1, r0)
LOAD(r0, mem + 0)
r0 = FOO(r0, r1)
There you have it: a fully allocated program in a single pass!
The big picture
Taking a more rigorous look, when we arrive at an operation, the output is located in either a register or memory; each input is either in a register, memory, or unassigned.
We need to make sure that all inputs and outputs are assigned to registers at the moment of the operation. To do so, we may need to evict existing register assignments to make room.
All of this boils down to very carefully placed LOAD and STORE operations
around the target operation; at one point, I wrote out all 18 possible
states for a two-input operation by hand to make sure I got them right.
(There are also special cases if an input is repeated!)
We'll dive into the code shortly, but first, let's take a little detour.
A cheap LRU cache
Picking which register to evict is an easy decision in a two-register machine. Real-world machines, fortunately, have more than two registers. For systems with more than two registers, how do we quickly decide which one to evict?
We expect a value that has been used recently to be used again soon; this is called "temporal locality".
Temporal locality suggests that we should avoid evicting values that have been used recently. I implemented a dead simple least-recently-used (LRU) cache using an array-backed doubly-linked list:
/// Dead-simple LRU cache, implemented as a doubly-linked list with a static
/// backing array.
///
/// <-- prev next -->
/// ------- ------- ------- --------
/// | a | <--> | b | <--> | c | <--> | head | <--|
/// ------- ------- ------- -------- |
/// ^ oldest newest |
/// |-----------------------------------------------|
pub struct Lru<const N: usize> {
data: [LruNode; N],
head: usize,
}
#[derive(Copy, Clone)]
struct LruNode {
prev: usize,
next: usize,
}
(who says Rust can't handle linked lists?)
Keeping the LRU cache in stack-allocated arrays – instead of nodes allocated in the heap, stitched together by pointers – improves its (CPU) cache friendliness.
Each of the N registers has a slot in the data array, with indexes 0
through N - 1. The prev and next indexes, when followed as indexes into
self.data, form a circular linked list; the index head is the newest node.
At this point, we can bring all of the usual linked-list algorithms to bear.
We'll initialize the list with self.head = 0, and implement node removing
and insertion:
impl<const N: usize> Lru<N> {
pub fn new() -> Self {
let mut out = Self {
head: 0,
data: [LruNode { prev: 0, next: 0 }; N],
};
for i in 0..N {
out.data[i].prev = i.checked_sub(1).unwrap_or(N - 1);
out.data[i].next = (i + 1) % N;
}
out
}
/// Remove the given node from the list
fn remove(&mut self, i: usize) {
self.data[self.data[i].prev].next = self.data[i].next;
self.data[self.data[i].next].prev = self.data[i].prev;
}
/// Inserts node `i` before location `next`
fn insert_before(&mut self, i: usize, next: usize) {
let prev = self.data[next].prev;
self.data[prev].next = i;
self.data[next].prev = i;
self.data[i] = LruNode { next, prev };
}
To mark a node as recently-used, we implement poke(...), which moves it to the
head of the list.
impl<const N: usize> Lru<N> {
/// Mark the given node as newest
pub fn poke(&mut self, i: usize) {
let prev_newest = self.head;
if i == prev_newest {
return;
} else if self.data[prev_newest].prev != i {
// If this wasn't the oldest node, then remove it and
// reinsert itright before the head of the list.
self.remove(i);
self.insert_before(i, self.head);
}
self.head = i; // rotate
}
}
To get the oldest item, we look to head.prev, then rotate the list, which
makes that node the newest.
impl<const N: usize> Lru<N> {
/// Look up the oldest node in the list, marking it as newest
pub fn pop(&mut self) -> usize {
let out = self.data[self.head].prev;
self.head = out; // rotate so that oldest becomes newest
out
}
}
These two functions are all we need for our register allocator: Whenever a
register is used, we poke it in the LRU cache; whenever we need to pick a
register to evict, we pop the oldest one (which has the side effect of marking
it as fresh).
The RegisterAllocator itself
Now, let's take a look at the RegisterAllocator itself. I'm not going to drag
you through every single line of code, but looking at the data structure should
clarify the plan.
First, our variable type from the SSA input:
#[derive(Copy, Clone, Debug, Eq, PartialEq)]
struct SsaVariable(usize);
impl SsaVariable {
pub const INVALID: Self = Self(usize::MAX);
}
Next, strongly-typed values representing various kinds of allocations
#[derive(Copy, Clone, Debug, Eq, PartialEq)]
struct Register(usize);
#[derive(Copy, Clone, Debug, Eq, PartialEq)]
struct Memory(usize);
#[derive(Copy, Clone, Debug, Eq, PartialEq)]
enum Allocation {
Register(Register),
Memory(Memory),
Unassigned,
}
Finally, the RegisterAllocator itself:
pub struct RegisterAllocator<const N: usize> {
/// Map from a `SsaVariable` in the original tape to the
/// relevant allocation
allocations: Vec<Allocation>,
/// Map from a particular register to the index in the original tape
/// that's using that register, or `SsaVariable::INVALID` if the
/// register is unused.
registers: [SsaVariable; N],
/// Our least-recently-used cache of registers
register_lru: Lru<N>,
/// Available registers
spare_registers: ArrayVec<Register, N>,
/// Available memory slots
spare_memory: Vec<Memory>,
/// Total allocated slots (registers and memory)
total_slots: usize,
/// Output slots, assembled in reverse order
out: Vec<AsmOp>,
}
Let's look at just one of the functions within RegisterAllocator: the
function which is responsible for handling a unary operation:
/// Lowers an operation that uses a single register into an
/// `AsmOp`, pushing it to the internal tape.
///
/// This may also push `Load` or `Store` instructions to the internal
/// tape, if there aren't enough spare registers.
fn op_reg(&mut self, out: SsaVariable, arg: SsaVariable, name: &str) {
let out = self.get_out_reg(out);
match *self.get_allocation(arg) {
Allocation::Register(lhs) => {
self.out.push(AsmOp::Unary { out, lhs, name });
self.release_reg(out);
}
Allocation::Memory(m_y) => {
self.out.push(AsmOp::Unary { out, lhs: out, name });
self.rebind_register(arg, out);
self.out.push(AsmOp::Store { src: out, dst: m_y });
self.release_mem(m_y);
}
Allocation::Unassigned => {
self.out.push(AsmOp::Unary { out, lhs: out, name });
self.bind_initial_register(arg, out);
}
}
}
There are a bunch of unexplained helper functions with descriptive names
(get_out_reg, get_allocation, etc), but the broad strokes should be clear:
- We get an output register by calling
get_out_reg, passing it theSsaVariableidentifier of the output. Under the hood, this checks to see if the output is currently bound to a register; if not, it makes it so. - Then, we examine the current allocation of the single input argument:
- If it's already bound to a register, then we use that register, then release the output register. Easy!
- If the input is in memory, then we reuse the output register immediately,
rebinding it to the input and adding a
Storeoperation before the target operation (considered in evaluation order) - If the input is unassigned, then we again reuse the output register, but
there's no need for a
Store; the input ends up bound to the former output register.
For all of the finer details, I'll direct you to the code, which has extensive docstrings explaining what's going on.
Before we move on, let's count the places that could perform allocation:
self.allocationsneeds to be big enough for every SSA variable. If we know the maximum SSA variable index in advance, it can be pre-allocated.self.spare_memoryis a stack of available memory slots. It could also be preallocated to a conservative value (something like 256 would be more than sufficient for my test models).- Finally, the output (
self.out) needs to fit every instruction in the resulting allocated code. This is harder to preallocate, because we don't know how many memory operations will be needed, but we could guess at a certain overhead (e.g. 20-30%).
It's worth noting that the RegisterAllocator itself could be reused, which
amortizes the allocation cost down even further!
A small showdown with Clang
I've been testing on a file with 6362 instructions, which begins
$14 = INPUT0()
$13 = MUL_IMM($14)
$6225 = ADD_IMM($13)
$197 = ADD_IMM($13)
$6361 = NEG($197)
$6360 = MAX($6225, $6361)
$6224 = NEG($6225)
$6357 = SQUARE($6224)
# ...and continues in this vein for some time
Running in a tight loop, I see roughly the following timing:
- File read (from disk, presumably cached): 31 µs
- Parse (from
StringtoVec<Op>): 2.7 ms - Register allocation (24 registers): 132 µs
- Serialize back to a
String: 0.8 ms - File write (to disk): 75-200 µs
Doing this 100×, the average round-trip time is 3.9 ms.
This is pretty great: our register allocation is already one of the fastest parts of the system, second only to reading the file!
(The parser is a total hack job, so I'm not surprised to see it underperforming)
The output is a fully-allocated script, written into out.txt:
# less out.txt
r12 = INPUT0()
r2 = MUL_IMM(r12)
r22 = ADD_IMM(r2)
r0 = ADD_IMM(r2)
STORE(r0, mem + 36)
r0 = NEG(r0)
r0 = MAX(r22, r0)
r22 = NEG(r22)
r13 = SQUARE(r22)
# ...and so on
You can see that instructions are in the same order as the input script, but
use registers instead of SSA variables; a single STORE operation is in
evidence, and both r22 and r0 are reused a few times even in this short
block of code.
Obviously, Clang cannot accept our homebrew scripting language. However, we can trivially convert it into a C program:
// Forward declarations of all our operations
float INPUT0(void);
float MUL_IMM(float);
float ADD_IMM(float);
float NEG(float);
// ... etc
float run() {
const float v14 = INPUT0();
const float v13 = MUL_IMM(v14);
const float v6225 = ADD_IMM(v13);
const float v197 = ADD_IMM(v13);
const float v6361 = NEG(v197);
// ...
return v0;
}
Using external functions forces the compiler to call them, meaning it can't get too clever with optimization. Since we've included parse + output time in our benchmarking of SSRA, this is a fair-ish comparison: the compiler also has to parse the input, perform register allocation, and write an output file.
(Of course, it's not totally fair, because the compiler is also doing codegen, but that should be pretty simple for this code. The goal here is a rough comparison!)
Compiling this to an object file, the disassembly looks familiar:
# cc -c -O3 run.c -o out.o && otool -XtvV out.o > out.s && less out.s
_run:
stp d15, d14, [sp, #-0x60]!
stp d13, d12, [sp, #0x10]
stp d11, d10, [sp, #0x20]
stp d9, d8, [sp, #0x30]
stp x28, x27, [sp, #0x40]
stp x29, x30, [sp, #0x50]
add x29, sp, #0x50
sub sp, sp, #0x1e0
bl _INPUT0
stur s0, [x29, #-0xb0]
bl _MUL_IMM
fmov s9, s0
bl _ADD_IMM
fmov s8, s0
fmov s0, s9
bl _ADD_IMM
str s0, [sp, #0xa8]
bl _NEG
fmov s1, s0
fmov s0, s8
bl _MAX
fmov s10, s0
fmov s0, s8
bl _NEG
stur s0, [x29, #-0x78]
bl _SQUARE
# ...etc
(I'm running on an M1 Macbook, so all of the assembly in this section is AArch64)
We see a function prelude (the stp instructions), followed by calls to our
dummy operations (beginning with bl _INPUT0). In addition, we see one register
being moved to the stack:
stur s0, [x29, #-0xb0]
It's more verbose than the pseudocode produced by SSRA – particularly because
arguments to our operations must be in s0 and s1 – but definitely has
a similar flavor.
How long did the compilation take?
$ time cc -c -O3 run.c -o out.o
real 0m0.369s
user 0m0.312s
sys 0m0.045s
By sheer coincidence, SSRA is almost exactly 100× faster (95×, to be precise).
With the disassembly, we can do a few other comparisons.
First, functions are called with bl or b instructions. Let's make sure we
have the right number of function calls, counting them with wc -l:
$ grep "\tb" out.s|head
bl _INPUT0
bl _MUL_IMM
bl _ADD_IMM
bl _ADD_IMM
bl _NEG
bl _MAX
bl _NEG
bl _SQUARE
bl _INPUT1
bl _MUL_IMM
$ grep "\tb" out.s|wc -l
6362
Sure enough, this matches the number of operations in our input!
Now, let's see how many memory operations were generated in the Clang code.
Memory operations use the ldr, ldur, str, and stur instructions:
$ grep -E "ldu?r" out.s|wc -l
1115
$ grep -E "stu?r" out.s|wc -l
431
We see 1115 loads and 431 stores.
Compare that with our generated code:
$ grep LOAD out.txt|wc -l
582
$ grep STORE out.txt|wc -l
582
Amazingly, our homebrew register allocator produces fewer memory operations in total: 1163, versus 1546 for Clang.
Or does it?
Remember, we performed register allocation assuming we had 24 registers
available. This is based on the A64 calling convention,
using floating-point registers 8 through 32. In this case, we're doing
single-precision floating-point operations, so the registers are indicated
with s, e.g. s8.
Now, which registers did Clang use? We can find out from the disassembly:
$ grep -Eo "s[0-9]+" out.s|sort --version-sort -u
s0
s1
s8
s9
s10
s11
s12
s13
s14
s15
It turns out that Clang only used 10 registers:
s0ands1are function arguments (per calling convention)s8throughs15are local variables- It refused to use
s16throughs32, which are "local variables, caller saved"
This was surprising!
I attempted to convince Clang that it could use all the registers by annotating
all of my dummy functions with __attribute__((preserve_all)).
This promptly crashed Clang:
$ cc -c -O3 run.c
fatal error: error in backend: Unsupported calling convention.
clang: error: clang frontend command failed with exit code 70 (use -v to see invocation)
Apple clang version 14.0.0 (clang-1400.0.29.102)
Target: arm64-apple-darwin21.6.0
Thread model: posix
InstalledDir: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin
clang: note: diagnostic msg:
********************
PLEASE ATTACH THE FOLLOWING FILES TO THE BUG REPORT:
Preprocessed source(s) and associated run script(s) are located at:
clang: note: diagnostic msg: /var/folders/r7/0hh1cx9925d9l33bwbv712fh0000gn/T/run-65434d.c
clang: note: diagnostic msg: /var/folders/r7/0hh1cx9925d9l33bwbv712fh0000gn/T/run-65434d.sh
clang: note: diagnostic msg: Crash backtrace is located in
clang: note: diagnostic msg: /Users/mkeeter/Library/Logs/DiagnosticReports/clang_<YYYY-MM-DD-HHMMSS>_<hostname>.crash
clang: note: diagnostic msg: (choose the .crash file that corresponds to your crash)
clang: note: diagnostic msg:
********************
(try it for yourself on Compiler Explorer)
At this point, despite having spent too much time on this writeup, I turned to
gcc.
GCC 12 runs in about 1.2 seconds, between 3-4× slower than Clang. However, it uses many more registers!
$ time gcc-12 -O3 run.c -c -o out.gcc.o
real 0m1.179s
user 0m1.099s
sys 0m0.062s
$ otool -XtvV out.gcc.o > out.gcc.s
$ grep -Eo "s[0-9]+" out.gcc.s|sort --version-sort -u
s0
s1
s2
s3
s4
s5
s6
s7
s8
s9
s10
s11
s12
s13
s14
s15
s16
s17
s18
s19
s20
s21
s22
s23
s24
s25
s26
s27
s28
s29
s30
(This is without __attribute__((preserve_all)), which has no effect)
Like Clang, GCC uses s8-15. Unlike Clang, GCC uses s16-30 (but not s31,
oddly enough); it also uses s2-7, which are defined as function arguments in
our calling convention.
So, does it successfully use those registers to minimize loads and stores?
$ grep -E "ldu?r" out.gcc.s|wc -l
1268
$ grep -E "stu?r" out.gcc.s|wc -l
569
Nope! Despite using 29 (non-argument) registers to Clang's 8, GCC ends up doing more loads and stores!
Performance summary
I collected a little more data and made a summary chart:
| Clang | GCC | SSRA[24] | SSRA[10] | SSRA[8] | |
|---|---|---|---|---|---|
| Runtime | 369 ms | 1.2 sec | 3.9 ms | 3.8 ms | 3.8 ms |
| Registers | 8 | 29 | 24 | 10 | 8 |
| Load | 1115 | 1268 | 582 | 1151 | 1424 |
| Store | 431 | 561 | 582 | 1151 | 1424 |
| Memory words | 139 | 117 | 102 | 116 | 118 |
Notes
- Register count:
- Ignores the argument registers (
s0ands1) for Clang and GCC - Selected by the compiler for Clang and GCC; user-specified for SSRA
- Ignores the argument registers (
- Memory words:
- Found by looking at load / store operations on
s*registers - Shown in words (
f32)
- Found by looking at load / store operations on
Commentary
The asymmetry between load and store counts puzzled me at first, until I realized what the compilers are doing: they're smart enough to leave a value in memory and load it multiple times; SSRA will only allow a value to be in one place at a time (register or memory).
Clang seems pretty impressive: given its self-imposed limitation of 2 argument + 8 scratch registers, it manages to use an impressively small number of loads and stores, at a slight penalty to stack space.
GCC is less impressive: it's allowing itself more registers than any other system, but is still generating a bunch of memory operations.
SSRA, in my humble opinion, is also impressive: it runs two orders of magnitude faster, and doesn't dramatically underperform the more powerful compilers. Even when limited to 8 registers, it's within a factor of 2x of Clang's load/store count (to say nothing of GCC).
Take all of this with a grain of salt: I'm not a compiler engineer, and there are probably good reasons for the choices that they're making. The real test would be benchmarking the generated code, which I'll classify as "future work".
(In particular, I'm curious whether loads are cheaper than stores, which would explain why the compilers prefer to keep copies of values on the stack; Performance Speed Limits suggests that's the case in steady-state loops. If you've got any insights, send me an email or ping me on Twitter).
Register pressure
Just for fun, here's a quick graph of register count against load/store operations:

This is running on the same 6362-operation program; at 24 registers, about 20% of the generated code is memory operations.
To keep every value in registers, we would need 126 of them!
Demo
Here's a second demo editor, with an extra slider to adjust register count.
24 registers
Conclusions and notes about this writeup
I went into this exercise unsure of whether I could improve on state-of-the-art compilers. It turns out that – for this very specific sub-problem – it's definitely possible!
The solid-state register allocator is a means to an end, and exists as a subcomponent in a larger (unreleased) system. If you'd like to hear when I publish more, subscribe via Atom or follow me on Twitter.
{kind=link}
The code for this writeup is all published on Github.
The main branch is what's running on this page; the bench branch includes
benchmarking in the test suite.
The repo is just sufficient to run the demos and benchmarks in this write-up – and isn't suitable for other applications – so I'm not releasing it on crates.io. If you want to do something similar, I encourage you to adapt the code for your own applications!
Benchmarking was done with native code, but the demos on this page use
wasm-pack to run the same code in the browser. Very casual benchmarking
reveals the overhead to be under 2× (the large sample program runs in 6.1 ms,
versus 3.8 ms for the native build).
Text highlighting is done with highlight.js and
a custom syntax file for the pseudo-assembly language.
The text editor with syntax highlighting was originally based on
this CSS-tricks writeup,
but evolved significantly since then;
look at the source for details if you dare (run.js, style.css).