Hunting a spooky ethernet driver bug
This is the story of a bug that took nearly a year to resolve. Like all the best horror stories, it includes twists, jump-scares, and the ability to overwrite arbitrary locations in RAM by sending carefully crafted packets over the network.
Context
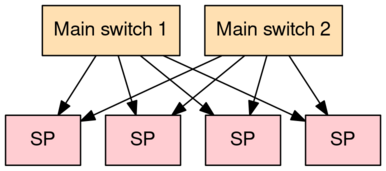
I work at Oxide Computer Company, which is building a "rack-scale computer". This means that our unit of compute – the thing you buy – is a rack with 32 servers and 2 network switches.
The rack is managed by service processors ("SPs"), which are STM32H7 microcontrollers. Think of the SP as a baseboard management controller; it handles thermal regulation, power control, and other lights-out management functionality.
Each SP is connected to the two rack-level switches on a secondary 100 MBit network. These connections between SPs and the rack-level switches are collectively named "the management network", and are critical for low-level system administration: it's the only way to talk to the SP in a production rack! This management network comes up autonomously at power-on (independent of any servers powering on), and should remain online at all times.
"Ethernet's haunted"
Every once in a while, we noticed an SP was no longer responding to packets on
the management network. Once broken, the SP would remain in this state until
the net task – responsible for configuring our ethernet hardware and software
stack – was restarted.
The issue never happened on the benchtop or during casual testing, but was triggered reliably during firmware updates on a rack.
We poked at the bug, but couldn't make any real headway. As a work-around, we
added a watchdog to the
system: if no packets were received in a 60 second interval, the net task
would restart itself, which consistently cleared the lockup. The management
network is quite chatty, so this didn't lead to spurious resets in a production
rack.
Mysteries in the DMA registers
Like most rare bugs, we only started making progress on the case after finding a way to reproduce it. My colleague John managed to set up a minimal reproduction environment: load a particular firmware onto the microcontroller, run a program on the host to ping it with a particular pattern of packets, and wait. Minutes-to-hours later, the netstack would lock up!
(My record was 6 hours before seeing a failure)
With the system in the broken state, I began going through the ethernet
registers one by one, looking for anything suspicious. The first hint appeared
in ETH_DMACSR, the DMA channel status register: it showed that there had been
an "error during data transfer by Rx DMA".
To understand what going on, we'll need a little background about how ethernet works on this microcontroller. Unlike SPI or I2C, ethernet data comes in so fast that we can't have user code processing each byte as it arrives. Instead, it is mandatory to use Direct Memory Access (DMA).
In this system, the peripheral hardware and user code have to work together: the peripheral hardware copies incoming packets into memory automatically, then user code processes them at its leisure.
User code has to tell the hardware where the packet data should go. It does so with what are called "descriptors". Each descriptor is 16 bytes (organized as four 32-bit words), with the following structure:
| Word | Value | |
|---|---|---|
| 0 | Buffer address (31:0) | |
| 1 | — | |
| 2 | — | |
| 3 | OWN (31) | — |
(skipping words and bits that are irrelevant to the story)
The first word in the descriptor contains the address to which the hardware
should write packets as they arrive. The other words are mostly irrelevant for
this discussion, except for OWN bit in the last word. This bit marks whether
the descriptor is currently owned by DMA hardware or user code. When it is set,
the descriptor is owned by the DMA hardware; when it is cleared, the descriptor
is owned by user code.
Descriptors are organized in a ring, which typically contains four descriptors. The hardware will automatically progress through the ring, doing something like the following:
- If the
OWNbit is cleared, suspend: we have reached a descriptor that is owned by user code and are not allowed to write into its buffer - Otherwise, wait for a packet
- Write the packet to the buffer specified in the descriptor
- Clear the
OWNbit, indicating that user software can process the packet - Move on to the next descriptor, wrapping around the ring if necessary
User code then does basically the same thing:
- Wait for the
OWNbit to be cleared (by hardware) - Process the packet out of the buffer
- Set the
OWNbit, handing the descriptor back to hardware - Move on to the next descriptor
With the basics of DMA covered, the flag of "error during data transfer by Rx DMA" should make more sense: something went wrong during the Rx DMA's attempt to copy data into a buffer, and the buffer address is provided by user code when it fills out the descriptors.
Fortunately, the hardware also tells us what address the peripheral was trying
to write when it failed. ETH_DMACCARXBR, the "channel current application
receive buffer register", had a value of 0x00000301.
To mis-quote the inimitable James Mickens,
Despair is when you’re debugging a kernel driver and you look at a memory dump and you see that a pointer has a value of [0x301].
On the upside, it's obvious why the DMA Rx channel is unhappy: trying to copy
data to 0x301 is not going to end well for anyone.
The jumpscare
Where did the value of 0x301 come from? It's certainly not the address of
any of our ethernet buffers, which are sensible things like 0x30024c0.
After poring over the code, I made the obvious choice to just search the entire repository and see where that constant appeared.
What happened next was the debugging equivalent of a jumpscare:
I'd like to thank my colleagues for their (emoji) support in these trying times:
VLANs in the management network
Taking a step back, you may be wondering why we're using VLANs in the system at all!
As we discussed earlier, each SP is connected to both of the rack's two main network switches. However, the STM32H7 only has a single physical ethernet interface. We use a small three-port switch, connected (on the downstream side) to this interface and (on the upstream side) to both main switches.
It's a pleasant abstraction to treat the two links as totally independent – basically pretending that the STM32H7 has two MACs – and this is where the VLANs come in! We configure the small three-port switch as follows:
- Packets coming from the main switches are prepended with a VLAN tag of
0x301or0x302, depending on which link they arrived on - Packets coming from the SP must include a VLAN tag of
0x301/0x302. The three-port switch strips this tag and only sends packets to the corresponding main switch.
The SP's software then runs two independent instances of the network stack
(smoltcp), dispatching packets to one
or the other based on their VLAN tags. Here's a packet arriving from switch 1
and being tagged with 0x301 before being sent to the SP:
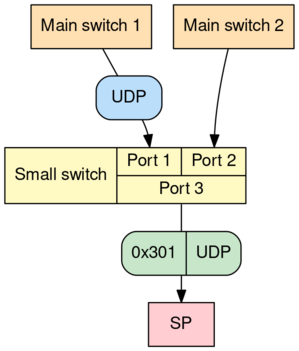
(If this diagram sparks joy, there are many others in RFD 250: Management Network Topology and Proprioception)
We configure the STM32H7's ethernet hardware to automatically strip VLAN tags from incoming packets. This means that packet data in memory is without any VLAN tags; the first bytes in the buffer are the IPv6 EtherType. How, then, does user software know what VLAN tag was associated with a particular packet when it arrived?
We previously talked about what user code writes to the descriptor before
handing it over to the hardware. It turns out that hardware also modifies the
descriptor (beyond the OWN bit), overwriting the descriptor with data in the
following form:
| Word | Value | ||
|---|---|---|---|
| 0 | Inner VLAN tag (31:16) | Outer VLAN tag (15:0) | |
| 1 | — | ||
| 2 | — | ||
| 3 | OWN (31) | — | |
(this is called a "write-back format" in the datasheet)
At this point, things are beginning to click into place: when a VLAN-tagged
packet is received, word 0 of the descriptor is written to 0x301. When the
descriptor is turned over to the hardware, word 0 is the memory address. Is it
possible that they're getting mixed up?
To the code
Our code looks correct: we always write the buffer address before setting the
OWN bit, with a memory barrier in between.
/// Programs the words in `d` to prepare to receive into `buffer` and sets
/// `d` accessible to hardware. The final write to make it accessible is
/// performed with Release ordering to get a barrier.
fn set_descriptor(d: &RxDesc, buffer: *mut [u8; BUFSZ]) {
d.rdes[0].store(buffer as u32, Ordering::Relaxed);
d.rdes[1].store(0, Ordering::Relaxed);
d.rdes[2].store(0, Ordering::Relaxed);
let rdes3 =
1 << RDES3_OWN_BIT | 1 << RDES3_IOC_BIT | 1 << RDES3_BUF1_VALID_BIT;
d.rdes[3].store(rdes3, Ordering::Release); // <-- release
}
Looking at the disassembly, it also looks reasonable:
; At this point:
; r8 contains the address of RDES0
; fp is our buffer address
; r5 is 0
80222e4: add.w r0, r8, #12 ; r0 gets the address of word 3
80222e8: str.w fp, [r8] ; write buffer address to word 0
80222ec: str.w r5, [r8, #4] ; write 0 to word 1
80222f0: mov.w fp, #3238002688 ; fp gets OWN | IOC | BUF1V
80222f4: str.w r5, [r8, #8] ; write 0 to word 2
80222f8: dmb sy ; memory barrier!
80222fc: str.w fp, [r0] ; write OWN | IOC | BUF1V to word 3
It's very hard to tell how this could be going wrong!
As an even more extreme test, I did the following:
fn set_descriptor(d: &RxDesc, buffer: *mut [u8; BUFSZ]) {
// At this point, the OWN bit is clear in d.rdes[3]; user code
// owns the descriptor and is in the process of releasing it
d.rdes[0].store(0x123, Ordering::SeqCst); // <-- this is new!
d.rdes[0].store(buffer as u32, Ordering::Relaxed);
d.rdes[1].store(0, Ordering::Relaxed);
d.rdes[2].store(0, Ordering::Relaxed);
let rdes3 =
1 << RDES3_OWN_BIT | 1 << RDES3_IOC_BIT | 1 << RDES3_BUF1_VALID_BIT;
d.rdes[3].store(rdes3, Ordering::Release); // <-- release
}
The address of 0x123 should never be seen by the DMA peripheral, because
it only ever exists in the descriptor when the OWN bit is cleared and the
descriptor is owned by user code. Nevertheless, after about five hours of
runtime, this failed with ETH_DMACCARXBR = 0x123.
(At this point, readers haunted by past experience may be wondering about caches; this is a great thought, but we also double-checked that they were all configured correctly!)
A horrifying realization
Up until this point, we assumed that the OWN flag was being used to
synchronize ownership between user code and hardware. After all, it's right
there in the name! In other words, we expected hardware to do the following:
- Check the
OWNbit - If the
OWNbit is set (i.e. the descriptor is owned by hardware), write packet data to the given buffer address
The OWN bit is in the last word of the descriptor, so this requires reading
rdesc[3] before rdesc[0]. This is kinda awkward, because it's out of
order from how the descriptor is laid out in memory.
My horrifying realization was that hardware could be reading the descriptor in order – and if it was doing so, it was possible for it to read an inconsistent descriptor, despite software doing the "right thing".
Here's the sequence diagram that came to me in a moment of terror:
| Hardware | User code |
|---|---|
Read rdesc[0] ⇒ 0x301 ⚠️
| |
Read rdesc[1] ⇒ ...
| |
Read rdesc[2] ⇒ ...
| |
Write rdesc[0] ⇐ buffer address
| |
Write rdesc[1] ⇐ ...
| |
Write rdesc[2] ⇐ ...
| |
dmb
| |
Write rdesc[3] ⇐ OWN
| |
Read rdesc[3] ⇒ OWN ⚠️
|
If reads and writes are interleaved just right, the hardware peripheral will
be persuaded that it owns the descriptor, and that it should write the next
packet to address 0x301.
Further experimentation convinced us that this was the case: there's a debug register that shows the DMA peripheral's internal state, and the issue only occurred when user code was modifying the descriptor at the same time as the hardware peripheral was fetching it.
With the bug identified, we can move on to finding a fix.
Or, we could have some fun.
Fun with VLAN tags
Right now, we send packets with a single VLAN tag, which means that we can corrupt the bottom 16 bits of the buffer address. This corruption allows us to disrupt the DMA peripheral, which is the issue we saw in the field.
If we enable nested VLANs, then we can control the entire 32-bit address: the two 16-bit ranges represents the inner and outer VLAN tags. This means that the DMA peripheral can be poisoned to copy the next packet anywhere in memory!
This would be much funnier, so I enabled the double VLAN feature and tested it
out.
I tested this by sending a packet with an outer VLAN of all zeros, and an inner
VLAN with VID = 1, DEI = 1, PRIO = 1. This is loaded into rdes[0] as
0x30010000, which is a valid memory address in SRAM1.
Normally, this memory is zero-initialized and unused. After running our attack
script for a few minutes, I see an attacker-controlled string (hello, world)
showing up in memory:
\/ 1 2 3 4 5 6 7 8 9 a b c d e f
0x30010000 | 0e 1d 9a 64 b8 c2 94 c6 91 15 77 b9 86 dd 60 0b | ...d......w...`.
0x30010010 | e8 67 00 46 3a 40 fe 80 00 00 00 00 00 00 96 c6 | .g.F:@..........
0x30010020 | 91 ff fe 15 77 b9 fe 80 00 00 00 00 00 00 0c 1d | ....w...........
0x30010030 | 9a ff fe 64 b8 c2 01 04 93 70 00 00 00 00 60 00 | ...d.....p....`.
0x30010040 | 00 00 00 16 11 40 fe 80 00 00 00 00 00 00 0c 1d | .....@..........
0x30010050 | 9a ff fe 64 b8 c2 fe 80 00 00 00 00 00 00 96 c6 | ...d............
0x30010060 | 91 ff fe 15 77 b9 1e 61 07 d0 00 16 6e 49 31 20 | ....w..a....nI1
0x30010070 | 68 65 6c 6c 6f 2c 20 77 6f 72 6c 64 1e 77 b5 99 | hello, world.w..
0x30010080 | 9b 37 30 30 94 bb c6 8f 23 85 df 06 d2 89 ff a4 | .700....#.......
0x30010090 | dc f9 0f 58 cd dd 84 eb ba 96 f6 3e 22 42 79 85 | ...X.......>"By.
0x300100a0 | 68 76 da fd 4f 80 02 7a 52 36 f0 41 ec 4a d3 8d | hv..O..zR6.A.J..
Very scary stuff!
The fix
Okay, that's enough fun for now.
Fortunately, it is possible to use the hardware safely!
The DMA configuration registers also includes the "Channel Rx descriptor tail
pointer register" (ETH_DMACRXDTPR), which – as it turns out – must be used
to protect descriptors when being written.
- The hardware peripheral stops processing descriptors when it reaches the one indicated by the tail pointer
- User code should update the descriptor, then update the tail pointer
- Updating the tail pointer triggers the hardware to re-read the current descriptor
In this configuration, the OWN bit still marks whether a descriptor is owned
by hardware or user code, but the tail pointer acts as the primary barrier to
prevent mismatched reads.
Dan implemented this fix in
our system, including
an exhaustive explanation
of why it works.
To the vendor's credit, the reference manual shows the tail pointer being used in this manner:
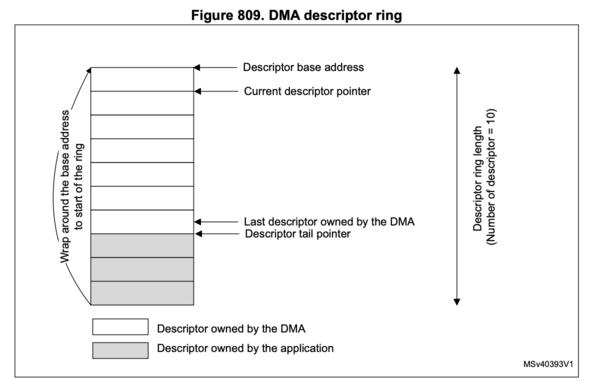
Unfortunately, this is mixed with factual inaccuracies about the hardware peripheral's behavior, making it hard to know what to trust. Their driver code also does us no favors in interpreting the documentation; it simply sets the tail pointer to 0 at all times.
Communication with the vendor
I filed a disclosure with ST's PSIRT, because we initially thought that this was a hardware bug in the peripheral with security implications. After about two months of radio silence, they came back with the same conclusion that we had reached in the meantime: this is not a hardware bug, because it's possible (and in fact, mandatory!) to use the tail pointer to protect the descriptor.
They do acknowledge that
It could affect the STM32H7xx_HAL_Driver as well as an application software created by a user that is not using STM32H7xx_HAL_Driver.
Indeed, as we observed above, the STM32H7xx_HAL_Driver sets the tail pointer
to 0 at all times, instead of using it to track ownership in the ring.
However, their driver also does not enable hardware VLAN tag stripping, meaning
it won't exhibit the issue: the first word of the descriptor is unchanged if tag
stripping is disabled.
As far as I can tell,
FreeRTOS + LwIP
and Zephyr are both using
STM32H7xx_HAL_Driver and fall into the same category: they do not properly
manage the tail pointer, but also do not enable hardware VLAN tag stripping.
stm32h7xx-hal
does use the tail pointer properly; well done!
We have encouraged ST to update STM32H7xx_HAL_Driver; even though the library
is not vulnerable in its current state, it's one configuration change away from
a spooky surprise!
Further reading
The bug itself contains the play-by-play and links to various other PRs. Congrats to @willglynn for initially flagging the tail pointer as a potential fix!
Post-publication updates
Embassy has updated their ethernet driver in response to this blog post.
ST published a technical advisory in March 2024 and has released an updated HAL driver with fixes for this issue.