It's Free Real Estate
Personally, I start getting nervous when my hard drive is below 10% capacity.
At my day job, our largest firmware image was at 96% of available flash space, after months of slowly creeping upward:
Used:
flash: 0xf6100 (96%)
ram: 0x4b800 (58%)
sram1: 0x4000 (12%)
Our microcontroller has a generous 1 MiB of flash, and we were using nearly all of it. Being low on flash isn't a crisis, but it's concerning: if we want to add more features in the future, we'd inevitably be slowed down by having to free up space for them.
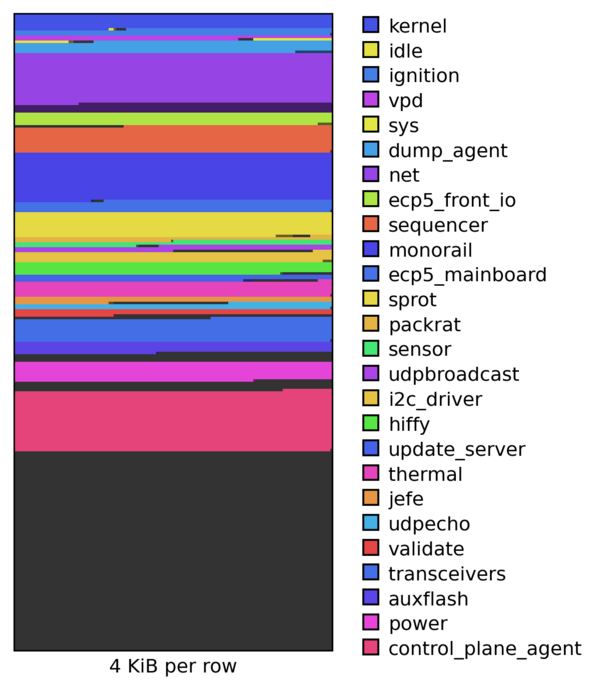
The firmware image in question is running Hubris, our in-house embedded OS. A Hubris image is built from a small kernel and a bunch of individual tasks, which communicate via IPC. In this specific image, we've got 25 tasks. Here's what they look like, laid out in flash memory:

There's a wide range of sizes, ranging from idle (a mere 256 bytes), all the
way up to net (occupying a whopping 128 KiB, 12.5% of our total space).
(For more background on Hubris, see Cliff's OSFC talk)
Memory protection in Hubris
In the visualization above, each task's memory allocation is a power-of-two size. Tasks are shown with two tones of the same hue: the brighter color is actual task code space, and the darker color is reserved space to make the total allocation a power-of-two size.
The power-of-two requirement is a result of how we use memory protection in our system. Each task is assigned independent regions of flash and RAM at compile time. At run time, the kernel configures the microcontroller's memory protection unit (MPU) so that tasks can only access their own memory; they can't touch each other or mess with internals of the kernel itself.
Using the MPU means that we have to obey its particular rules. For this microcontroller, the rules are as follows:
- The MPU can operate on a maximum of 8 regions at a time. The active regions are configured by 8 "MPU slots".
- Each region must be a power-of-two size.
- Each region must be aligned to its native alignment, e.g. a 4 KiB region must begin at a 4 KiB-aligned memory address.
Obeying these rules wastes a lot of space: if a task grows from 4095 to 4097 bytes, it will be padded all the way to the next power of two, i.e. 8192 bytes. The example above spends 344736 bytes padding out tasks, and 4800 bytes in aligning task regions, for a total of 341 KiB – which is over a third of our total memory!
Allocating 1½ regions for flash
Because the MPU has a maximum of 8 regions, we had considered allocating an extra MPU region to flash. This would let the task size be expressed as a value in the form 2ᵃ + 2ᵇ, which is a tighter bound than the next power of two.
This never quite got off the ground, because it was going to be awkward to implement: some tasks already used every single MPU slot because they controlled a bunch of memory-mapped peripherals, so we'd have to keep supporting single-slot tasks as well, and the whole thing just felt too messy.
A new perspective
One morning, I had a revelation:
Instead of supporting either one or two MPU slots for flash, we could implement the general case of N slots.
In other words, each task could allocate every spare MPU slot to flash.
("I paid for the whole MPU, and I'm gonna use the whole MPU")
It seems obvious in retrospect, but solving the more general problem ended up being significantly easier than a 1½-region special-case implementation. Tasks with no spare MPU slots would continue to use a single flash region (i.e. no worse than before), but that was now a particular instance of the N-region problem.
The implementation was tedious, but relatively straight-forward: we split each task's flash size into a sum of N powers of two, then pack them into memory with a simple heuristic that tries to maximize alignment at each step.
The packing algorithm has quadratic complexity, because it checks every task at each step to pick the best. Normally, I'm a stickler for avoiding accidentally quadratic behavior; however, in this case, we don't expect unbounded task growth, and the implementation runs in under a millisecond.
(If you're curious, see hubris#1599: Multi region packing for the actual code)
How does this perform?
This optimization knocks 280 KiB from our largest image, bringing us down to a comfortable 68% occupancy:
Used:
flash: 0xb0100 (68%)
ram: 0x4b800 (58%)
sram1: 0x4000 (12%)
Our new image has 43872 alignment bytes and 17344 task padding bytes, for a total of 60 KiB of padding (down from 341 KiB).
The difference is visually obvious in the packing graph, where per-task padding has basically disappeared:
It's also fun to look at the memory map, which breaks down exactly how tasks are packed into multiple contiguous regions:
flash:
ADDRESS | PROGRAM | USED | SIZE | CHUNKS | LIMIT
0x08000000 | kernel | 25792 | 25792 | 25792 | (fixed)
0x080064c0 | idle | 84 | 96 | 64 | 128
0x08006500 | | | | 32 |
0x08006520 | -padding- | -- | 128 | -- |
0x080065a0 | ignition | 10836 | 10848 | 32 | 16384
0x080065c0 | | | | 64 |
0x08006600 | | | | 512 |
0x08006800 | | | | 2048 |
0x08007000 | | | | 4096 |
0x08008000 | | | | 4096 |
0x08009000 | vpd | 6980 | 7008 | 4096 | 8192
0x0800a000 | | | | 2048 |
0x0800a800 | | | | 512 |
0x0800aa00 | | | | 256 |
0x0800ab00 | | | | 64 |
0x0800ab40 | | | | 32 |
0x0800ab60 | -padding- | -- | 160 | -- |
0x0800ac00 | sys | 1736 | 1792 | 1024 | 2048
0x0800b000 | | | | 512 |
0x0800b200 | | | | 256 |
0x0800b300 | -padding- | -- | 256 | -- |
0x0800b400 | dump_agent | 18976 | 19456 | 1024 | 32768
0x0800b800 | | | | 2048 |
0x0800c000 | | | | 16384 |
0x08010000 | net | 82760 | 98304 | 65536 | 131072
0x08020000 | | | | 32768 |
...etc
In short, this buys us a ton of breathing room at basically zero cost!
The other shoe drops
I hit the merge button with slight trepidation. Going from 1 to N flash regions is theoretically straight-forward, but is a significant change to the Deep Magic of our system.
While working on the PR, I assuaged myself with
exhaustive assertions:
we won't make it out of allocate_region unless the allocation is correctly
sized, aligned, and contiguous.
What I didn't expect was for this change to kill the network switch two months later; head on over to Cliff's blog for the details!