Higher-order reactive graph programming
After a few months of work since my last post, I'm developed a satisfactory model for higher-order reactive graph programming.
This post walks up the ladder of graph programming power, concluding with my latest scheme.
Level 0: Single script
At level 0, there is no graph to speak of; instead, there's a single script. When you edit the script, it is re-run.
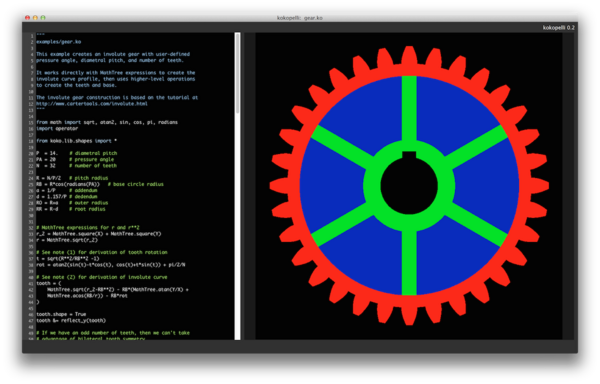
kokopelli is a level-0 system:
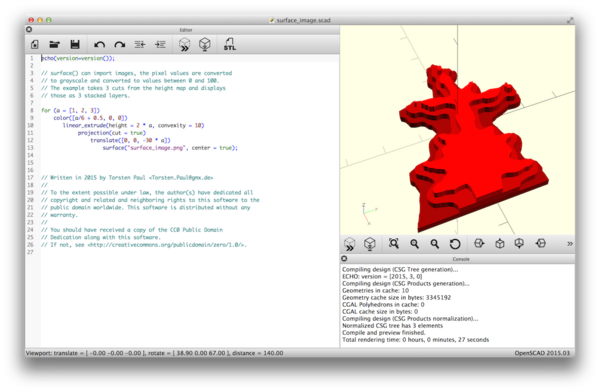
So is OpenSCAD (though it requires you to press a button to re-evaluate):
Though this is level 0 in terms of reactive graph programming power, it's a perfectly acceptable state of affairs: the user has an arbitrary script to work with, and can build up abstractions (custom functions, etc.) as needed for their design.
Level 1: Set of cells
At level 1, you have a flat set of cells, each with a unique name and script.
These cells exist in a particular namespace and can refer to each other by name. These accesses are tracked and changes are propagated automatically.
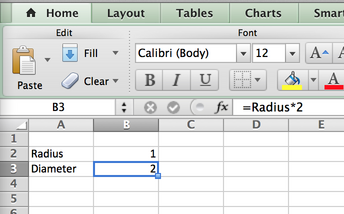
The most common example of a level-1 system (as it is commonly used) is Excel:
At this stage, detecting loops becomes necessary.
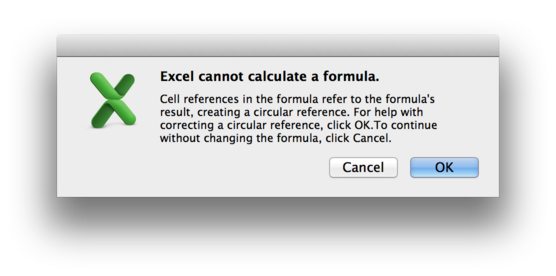
If you try to set up a recursive system of cells in Excel
(A1 = B1 + 1; B1 = A1 + 1),
it will detect this and give you a warning:
Of course, you can do level-1 design work in my tools as well. Here's a circle:
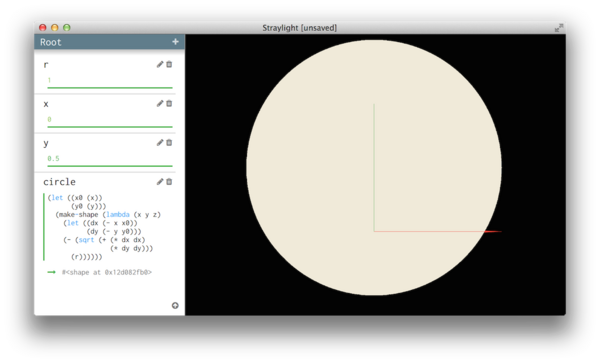
Notice the use of thunks as a way to track dependencies. The expression
let ((x0 (x)) ...
looks up x in the local namespace, records that we looked it up,
and binds its value to the variable x0.
This way, when x changes,
everything that looked it up is marked as dirty
(and queued up for re-evaluation).
This is necessary to keep the graph synched:
we want it to be a timeless representation of the system,
but optimized under the hood to only update cells as needed.
Level 2: Nested sheets
Here's where things start to get interesting.
Instead of having a flat namespace of cells, we now allow sheets to be nested, producing something like this:
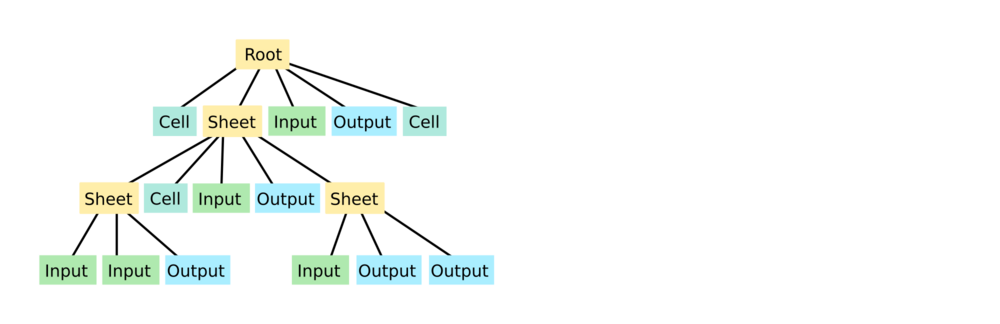
Inputs and outputs are special types of cells that interact with the parent level of the graph:
- Inputs are evaluated in the parent's namespace
- Outputs are available to other nodes in the parent namespace
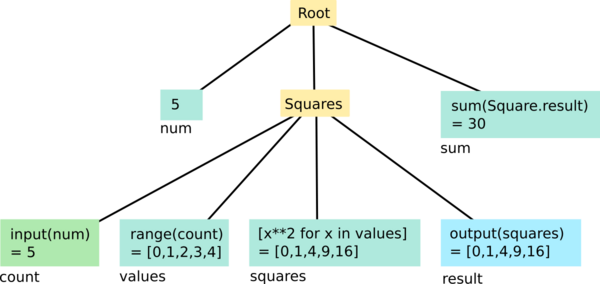
Here's an example of a nested system, demonstrating inputs and outputs:
count(lower-left) is an input, so it can readnumfrom the parent levelresult(lower-right) is an output, so its value is available in the parent
This kind of hierarchy helps in adding abstraction to large systems.
Graphene is an example of a level-2 system, as is Antimony.
It's a reasonable amount of power, but not quite the top of the ladder.
To understand why,
think about what happens if you want to re-use Squares
(and generate a different number of terms):
you have to copy-and-paste it as a new sheet,
and changes to the logic of Squares itself won't be
synched from one version to the other.
Level 3: Introducing instances
This level addresses the re-use question above by separating the definition of a sheet (as an object with inputs, internal cells, and outputs) from its instantiation.
Here, you can think of a sheet as a pure function: it takes in some set of inputs and converts them into some set of outputs.
Here's the same example as before, but instantiating an instance of Squares:
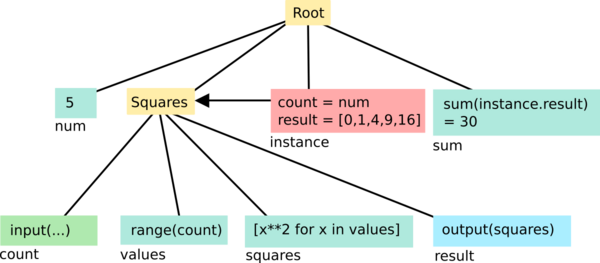
On first glance, this looks like the previous pictures, but with an extra box labelled "instance" that's pointing to the Squares sheet. The extra power becomes more clear when we add a second instance (and remove peripheral cells):
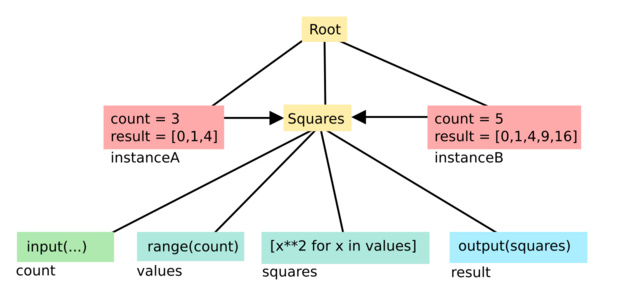
Now, we have two instances of the Squares sheet, with different inputs and outputs! This solves the re-use problem that we ran into in level-2 systems.
Of course, solving this problem introduces new complexities.
Since we're building a reactive graph, we want to store intermediate values for all cells (which are the boxes labelled "count", "values", "squares", "result", etc.). In the level-2 graph, these intermediate values are stored in the cells themselves. At level 3, it's less obvious where they live: "count" is both 3 and 5!
The solution I've chosen is path-dependent values. Instead of storing a single value, a cell stores a map from path to value. "Path" refers to the ordered list of instances to go from the root of the graph to a particular cell.
In the example above, "count" would have two values:
- ["instanceA"] maps to 3
- ["instanceB"] maps to 5
The same is true for "values", "squares", and "result".
This raises interesting UI questions of how to show values.
I've chosen to show the path-dependent values when you're looking into a particular instance. Here's the example above, showing two different views into instances of Squares:
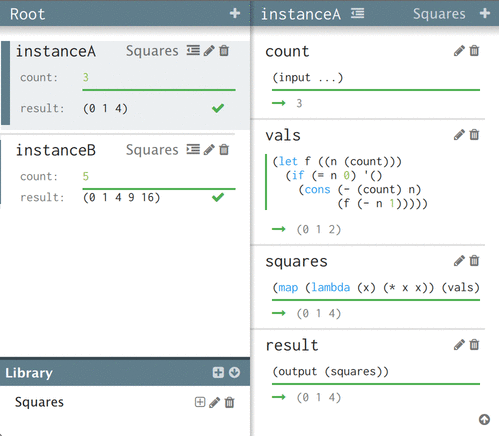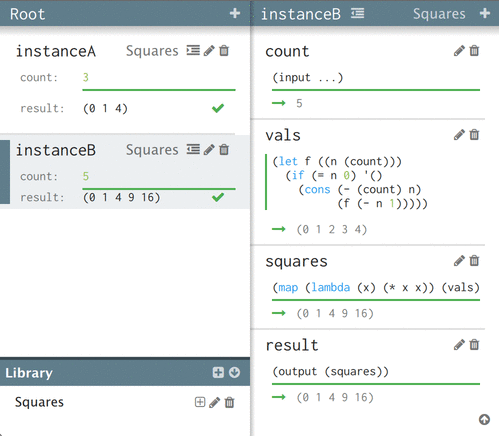
The expressions are the same, but the values (shown below each expression) are different depending on your perspective into the graph.
We've now covered nearly everything, but there's one more capability and one more concern to address. Both are related to the "sheets-as-functions" analogy.
First, the capability: we should be able to call a sheet in a cell's script, rather than instantiating it outright. Imagine if we want to create a set of n circles, where n is some integer parameter. Since n is unknown, we can't create that number of instances in the graph; instead, we need to call the sheet as a function. In practice, this can be done by building up a temporary instance, providing it with appropriate inputs, then recording its outputs and returning them to the script.
Here's an example, showing a script that calls "Circle" multiple times (generating a list of shapes), then passes that list into a Union operation:
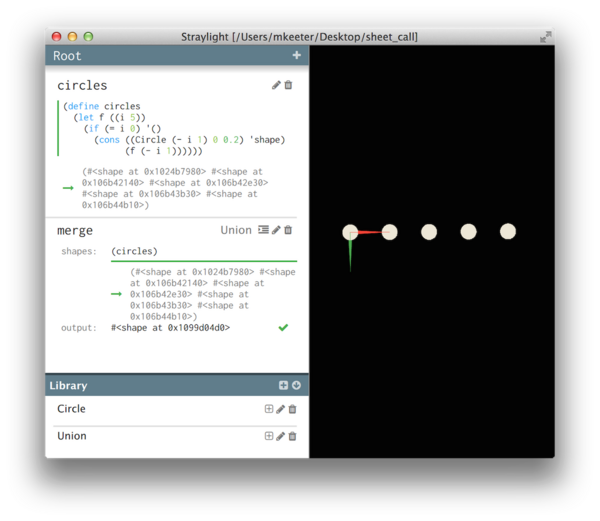
Now, the concern: We now need to check, before inserting (or calling) an instance, that doing so won't create a recursive loop. This wasn't a problem when building pure trees, but we now have the power to create systems that loop back onto themselves.
If A contains an instance of B, then we can't insert an instance of A into B, otherwise the graph would end up infinitely large. By analogy to function calls, this is recursion, but since we build the graphs explicitly (for efficient as-needed updates), it can't be allowed.
Conclusion
This is the top of our graph-programming-power ladder!
Going higher would entail allowing cells to modify the graph itself; I haven't thought through the implications well enough to formalize this.
My current level-4 system is on Github here, but isn't yet ready for public consumption; browse the vaguely-documented graph code here.
An exercise for the reader
I suspect that one could represent a set of path-dependent value as an Applicative, which would lead to a particularly elegant system for updating values (without having to iterate over every possible path to a cell).