About
In my spare time between late 2019 and early 2020, I wrote a technical paper which was accepted to SIGGRAPH and published in the ACM Transactions on Graphics.

SIGGRAPH/TOG is, by all accounts, the best research venue in computer graphics, so I was aiming a bit high, but a man's gotta have hobbies.
This writeup is a behind-the-scenes look at the experience. For example, you'll learn why 3/5 reviewers recommended rejecting the paper, and how I managed to change their minds in my rebuttal.
Hopefully, this will help folks considering a similar path; this information is normally passed down through academic research groups, so it's hard to know what to expect as an independent researcher.
What's the paper about?
(If you've read the paper, skip to the timeline)
You can read it (PDF, 4.6 MB), but I'll present a summary here.
The paper presents a new way to render closed-form implicit surfaces on the GPU.
Our implicit surfaces are defined by a function $f(x, y, z)$ which can be evaluated at any point $(x, y, z)$ in space. Where the function is negative, we're inside the shape; where the function is positive, we're outside the shape. The boundary of the shape is the isosurface $f(x, y, z) = 0$.
"Closed-form" means the function is built from a bunch of math operations, e.g.
$$\max\left(0.5 - \sqrt{x^2 + y^2}, \sqrt{x^2 + y^2} - 1\right) < 0$$
(rather than a more powerful representation that supports looping or branching)
This is a simple and homogeneous representation, though it's very low-level. Think of it as an assembly language for shapes: painful to write manually, but a reasonable target for higher-level tools.
We take this representation and convert it into a directed acyclic graph, which deduplicates common subexpressions:
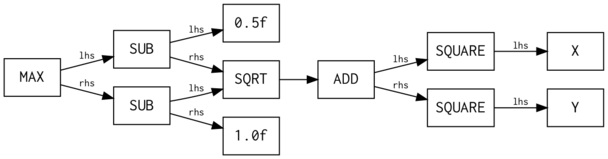
Then, we convert this graph to a tape, which is straight-line code that's equivalent to the DAG. In this step, we perform register allocation when deciding where to store intermediate results.
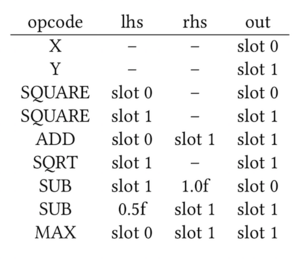
We upload the tape to the GPU, where the interesting work happens!
We evaluate the tape using interval arithmetic, which lets us check whether a particular region is inside, outside, or on the shape's boundary. Since we're on the GPU, this evaluation is done for many regions in parallel.
For regions that are ambiguous, we subdivide them and recurse. While recursing, we prune the tapes to only contain active clauses, which lets us do much less work in evaluating.
This evaluation process subdivides down to individual pixels / voxels, which are then evaluated directly. In 3D, we also use automatic differentiation to estimate surface normals.
Here's what this looks like in 2D, rendering a quarter-circle:
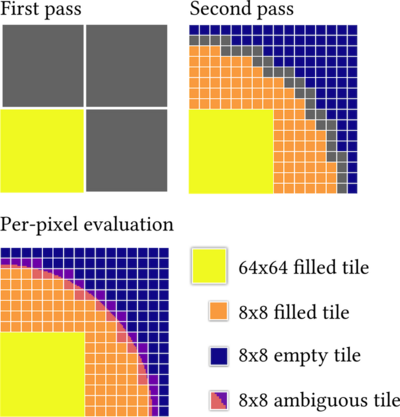
At a high level, this is all very similar to Interval Arithmetic and Recursive Subdivision for Implicit Functions and Constructive Solid Geometry (Duff '92). The interesting part of my paper is in adapting this algorithm (which is deeply recursive with heterogenous workflows in each branch) to run well on GPUs, plus a bunch of real-world implementation details and benchmarks.
The pipeline works in both 2D and 3D. In 2D, it produces black-and-white images, while in 3D, it produces heightmaps and normals:

The paper concludes with benchmarking results and directions for future research.
Timeline (2019-2020)
Writing this paper filled about six months of my nights-and-weekends spare time, with a mix of development, writing, editing, and waiting.
May (2019) and earlier
Back in grad school, I worked on software for computer-aided design using functional representations as the underlying model representation.
After graduation, this work continued as a long-running side project, with a few design tools and an open-source kernel that's used in both open-source and commercial CAD packages. I'd made various attempts over the years to put rendering on the GPU, but without any success until now.
The most recent, successful work was inspired by this blog post in May 2019. I read through the blog post, then skimmed the cited research papers and reference implementation, and started pondering whether a similar strategy could work for functional representations.
October-December (2019): Implementation
The first tangible hints of this project are an October 11th entry in my engineering notebook, boldly titled "GPU-Accelerated F-Rep Rendering" (click for full resolution).

The fascinating part, looking back, is how close this turned out to be – it's not exactly what I ended up implementing and writing up, but it's about 90% of the way there.
I started development on October 14th. Out of the gate, I decided to use CUDA for GPU acceleration: I've got an Macbook Pro from the NVIDIA days, so CUDA runs on it, and I didn't want to make my life harder than necessary. This would prove to be a good decision, because I'd later use the same code to benchmark on more powerful Linux workstations.
(As a side note, I have no idea what I'll do when this laptop dies – I like Apple's hardware and software, but also like being able to do cross-platform development)
The project started as a purely 2D renderer. Like most GPU projects, it had particularly aesthetic glitches:

(October 26-29)
By mid-November, the core 2D algorithm was working, and I began implementing a demo GUI. This was motivated in part by an upcoming visit to my old research group: I wanted to show them what I was working on and get their feedback.
By November 17th, the GUI looked like this:
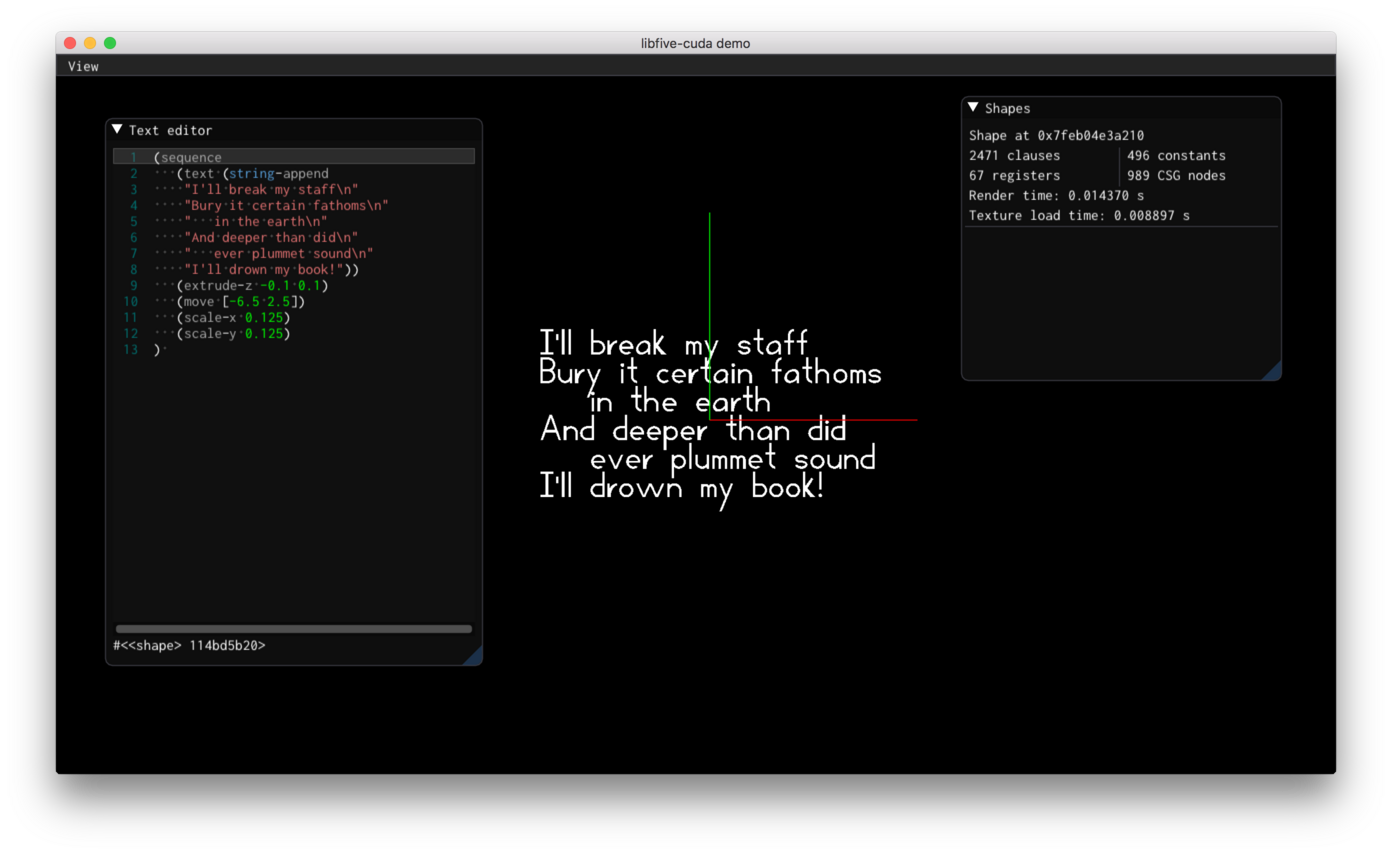
This reuses the Scheme bindings and standard library from libfive
which was a huge time saver.
The visit to CBA went well. I had already convinced myself that I need 3D rendering to make this a good paper, and they agreed. Neil also suggested benchmarking against a brute-force renderer, which led to Figure 5 in the final paper.
By November 27th, I had implemented 3D rendering:
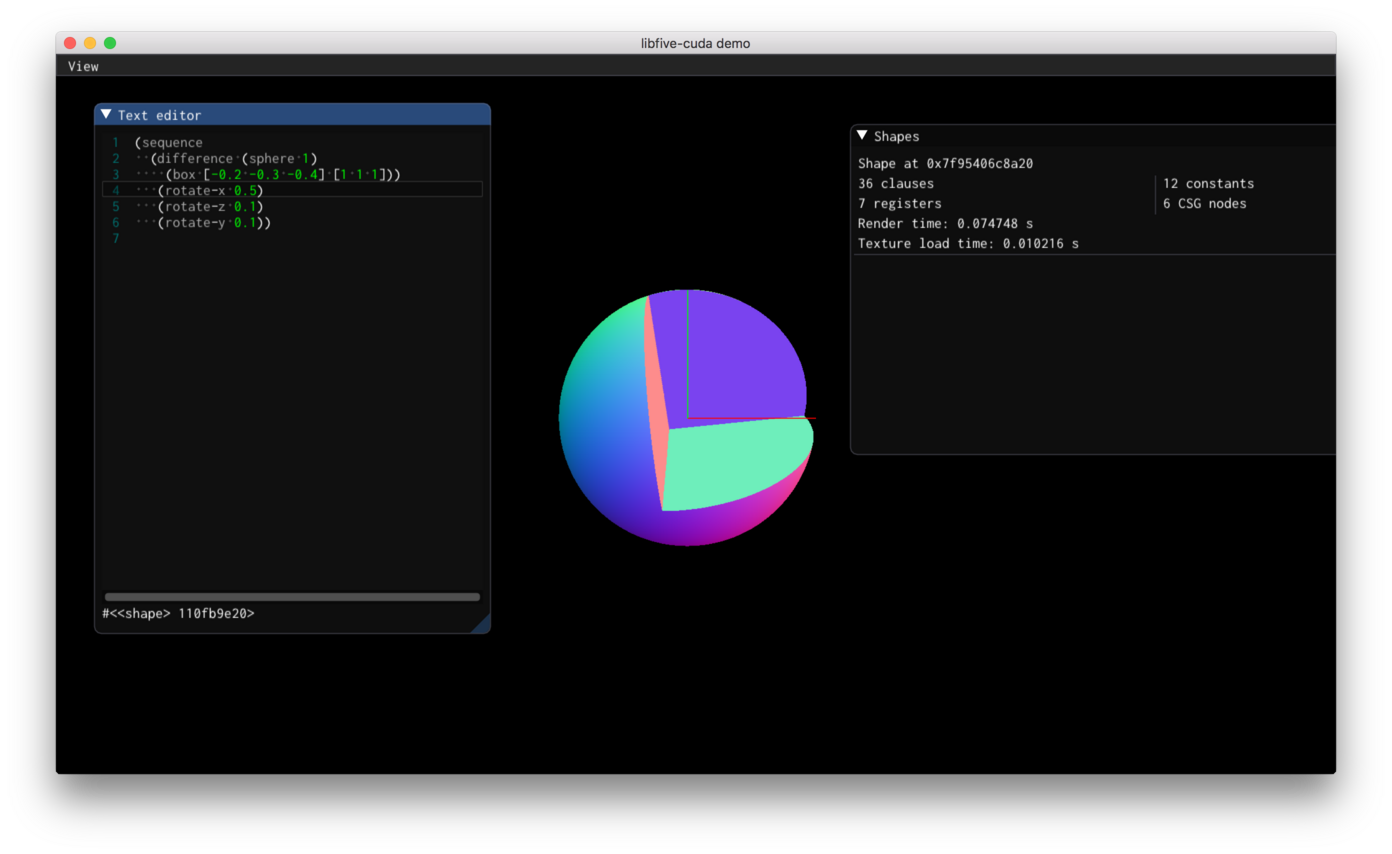
At this point, I switched gears and started working on the paper itself.
December (2019) - January (2020): Writing the paper
The first commit in the paper repository is dated to December 1st.
There's a fair amount of infrastructure involved in writing a technical paper.
- LaTeX (which I already knew)
- The
acmartdocument class - Using BibTex to track sources
- Writing a
Makefileto compile the paper
None of this is hard, but it's time-consuming to learn and set up. This page is a great (if somewhat overwhelming) list of things to keep in mind when writing a technical paper. How to Get Your SIGGRAPH Paper Rejected is another good reference, as is What Makes a (Graphics) Systems Paper Beautiful.
I also leaned heavily on reading past papers, not just for content, but for form. Alec Jacobson's research group has published consistently strong SIGGRAPH papers, and I often referred to the TetWild paper (PDF) when I had questions of style.
I traditionally visit family over Thanksgiving, then stay in Boston over Christmas break for some downtime. This year, writing the paper was my major project. It's hard to say exactly how much time went into the writing of the paper, but I spent a hour or two each evening working on it.
Citing previous work
I was extremely nervous about this section of the Technical Papers guidelines:
...a paper may also be rejected [before review] if it solves a problem that is known to be already solved; does not cite (and the authors seem unaware of) important prior work on the same problem and doesn't address how it is different;...
This nervousness led to me spending a lot of time reviewing previous papers, then tracking down their sources, and so on. I didn't read every word of every cited paper, but I certainly looked at a lot of prior research, both for inspiration and to compare against in the "Prior Work" section of the paper.
(Even then, I got called out by the primary reviewer for citing "obscure" references instead of more standard ones)
Finding interesting demo models
In the mesh world, there's a long list of common models. Sadly, there's no equivalent for implicit surfaces, and despite my enthusiasm for 3D graphics, I'm a terrible 3D artist.
I tackled this from several angles. First, I made a relatively straight-forward copy of the Bethesda Terrace and Fountain:

(based on a previous design by my wife)
Second, I reached out to Hazel, who has contributed to Studio in the past; she graciously shared a bear head sculpture to use as an example in the paper:

This model is a particularly challenging benchmark for my algorithm, because it's built of smooth operations which can't be culled, unlike hard-surface CSG modeling.
Finally, I dug up an involute gear model that has followed me around since 2013, which is an interesting middle ground: it's primarily CSG, but uses expensive trigonometric functions.

Of course,
the pattern of the three gears is a tribute to the venerable
glxgears.
Making pictures pretty
In early December, I made a second visit to CBA to show off 3D rendering. The main advice from this visit was that I needed snazzy demo pictures. In light of this feedback, I implemented two new features:
- Rendering with perspective
- Screen-space ambient occlusion
Benchmarking
Since this was a systems paper, I wanted to present benchmarking results to examine performance and scaling. More importantly, the whole point of this research is to render things fast, and my 2013 Macbook wasn't powerful enough to claim "interactive framerates" with a straight face.
Martin Galese – a long-time friend – founded Patentmark, a startup which uses machine learning to improve the patent review process. As part of this work, he's got a hefty VR/ML workstation in his basement to train ML models. He was kind enough to give me an account on the machine, so I could SSH in and run benchmarks on a relatively recent GPU.
This machine has a flagship 2017 GPU (NVIDIA GTX 1080 Ti) but I was left wondering whether I could get access to anything bigger.
As it turns out, AWS will give you a Tesla V100 for a mere $3.06/hour. This is a truly absurd GPU, intended for training deep learning models.
Interestingly, AWS will not let a brand-new account create any of their GPU servers. The error message also points you in the wrong direction; this Reddit post pointed me in the right direction of asking for a vCPU increase, rather than a machine instance increase.
I opened a very awkward support ticket asking for them to increase my limits for this machine type ("hello, I'm a real person, not trying to mine cryptocurrency"). The increase was approved after a three-day delay.
Since the machine is expensive to keep turned on, I ran benchmarks on my laptop and Martin's workstation during day-to-day development. Once I was relatively confident in the state of the code, I'd turn on the server for just long enough to pull, rebuild, and re-run benchmarks.
All in all, I spent $20.53 on AWS over the entire project:
- December: $3.73
- January: $2.82
- February: $2.00
- March: $7.94
- April: $4.04
March was expensive because I was rewriting the evaluator, and kept finding new optimizations and needing to regenerate results.
Generating figures
I normally use Matplotlib for graphs, but it's not obvious how to embed its results into LaTeX. I could export a bitmap (but that's no longer a clean vector representation) or export a PDF (which mixes Matplotlib's typesetting with LaTeX's); both of these options are sub-optimal.
Luckily, I found an article
describing how to use .pgf files,
which are a vector representation that offloads typesetting to LaTex –
this ended up being exactly what I wanted.
I created one folder per figure, containing raw data plus a Python script to generate the figure. The Python scripts were very hacky, with lots of manually setting size and positioning things to look right when embedded in the final document. Still, the resulting figures are lovely, and blend in perfectly with the text:
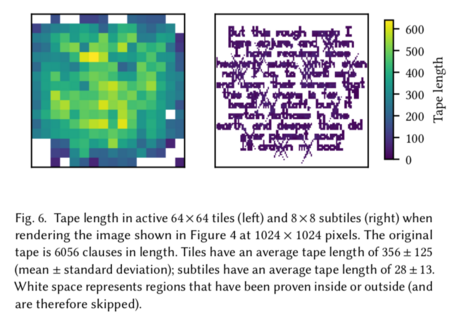
The colorbar numbers and caption are built into the figure, but typeset by LaTeX using the document font; the caption is part of the paper source.
I also used Inkscape for Figure 2, a vector-art illustration, exporting to PDF so that I could embed it losslessly into the paper. The equation diagram (Figure 3) was done in Graphviz, also exported to a PDF.
Per Hofstadter's Law, this all took longer than expected. I ended up writing thirteen small applications to do benchmarking, data generation, printing tables, and so on:
brute render_2d_heatmap render_effects
circle render_2d_table tape_building_time
dump_tape render_3d tape_shortening
print_tape_table render_3d_heatmap
render_2d render_3d_table
Getting feedback
In mid-December, I starting putting out feelers for beta readers. I ended up with five volunteers, ranging from fellow f-rep enthusiasts to industry practitioners to university professors.
To avoid burning out my volunteers, I sent each major draft to a different subset of readers. All in all, I sent out three drafts, on December 26th, December 31st, and January 6th.
I'm incredibly grateful for their feedback, and recognize that I'm lucky to have such a supportive network of friends and colleagues. If you find yourself in a similar situation of needing feedback on an independent research project, shoot me an email and I'll try to help.
January: Submitting the paper
The deadline for the paper was January 22nd, and I wanted to finish early, because the website warns about the servers slowing down near the deadline.
There are bunch of extra things that you can do, in terms of supplemental material. The most typical is making a demo video of your paper, to illustrate your work and hopefully end up in the annual Technical Papers Trailer.
I didn't do this, due to lack of time and resources as a solo author. Looking back after having made a 30-second Fast Forward video and a 20-minute pre-recorded talk, this was definitely the right choice; making videos is hard.
I submitted the paper on January 12th, ten days before the deadline.
As it turns out, you have to deliver more than just the bare PDF: the Technical Papers Committee also needs a "Representative Image", which is used in various places as a quick representation of the paper.
My final representative image looks like this:
(as you can see, graphic design is my passion)
I received an email saying my paper was "under evaluation" on January 25th, and breathed a sigh of relief – I hadn't screwed up egregiously enough to be rejected out of the gate.
February
While waiting for reviews to come in, I read a very interesting article about high-performance interpreter architecture. Since the core of the renderer is an interpreter loop, this was relevant to my interests!
I spent a few weeks revisiting my implementation, and ended up improving performance by 30-50% compared to the results submitted in the paper.
The improvements didn't stem from the M3 architecture (which is less effective on the GPU), but rather from realizing that CUDA is very sensitive to register count: if you have more than 32 registers per thread, you can't reach 100% GPU occupancy. I fine-tuned all of the kernels to stay under this limit, and was very pleased with the results.
March
On March 10th, the reviews came out.
3/5 of my reviewers recommended rejection:

Reading the reviews was humbling, in all senses of the word: the reviewers are clearly experts in the field, and they put significant effort into reading and thinking deeply about my work.
One major piece of feedback – and the reason I didn't immediately abandon all hope – is that I didn't actually present the rendering algorithm in the paper! I presented all of the pieces, then left it to the reader to put them together on their own, because it was obvious to me.
At this point, there's a 3-4 day period to write a rebuttal, which gets sent to the committee before final decisions are made. This writeup was incredibly helpful in writing the rebuttal, and this is another useful resource. My rebuttal ended up with two long replies (paragraph-length, including presenting the rendering algorithm), two short replies (2-3 sentences each), and a dozen very short replies to line-by-line feedback.
The rebuttal is limited to 1000 words, and mine was... 1000 words. By the end, I was shuffling and rephrasing sentences to free up words for use elsewhere in the doc.
Notably, I didn't mention the performance improvements in the rebuttal, based on the advice linked above.
I submitted the rebuttal on March 13th, and settled in to wait.
Two weeks later, on March 27th, the Technical Papers Chair sent out this email:
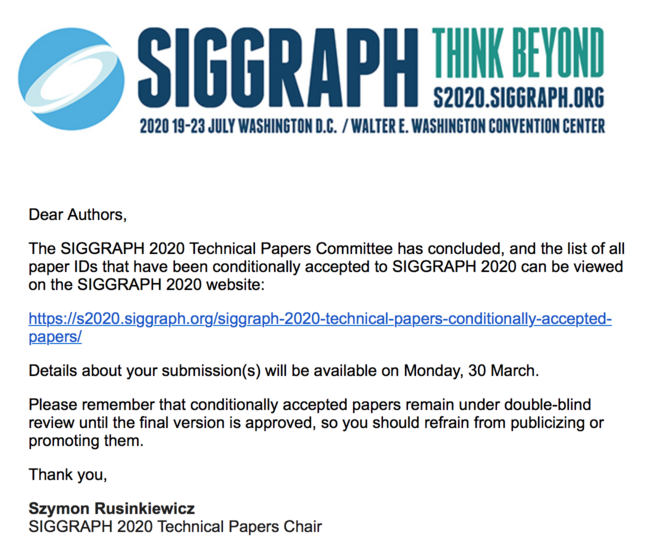
I clicked through to the document, and saw a three-page list of paper IDs:

My paper had submission ID 324, and the list contained papers_324,
so I was pretty sure this meant it's been accepted.
At this point,
I ran around my apartment a little bit until the adrenaline wore off.
After a long, slightly nervous weekend, I received a more personalized email:
Congratulations! Your paper, papers_324s2, titled: Massively Parallel Rendering of Complex Closed-Form Implicit Surfaces, has been conditionally accepted to SIGGRAPH 2020.
April - Revisions
SIGGRAPH only offers two results: rejection, and conditional acceptance. With a conditional acceptance, the author(s) are expected to make revisions based on feedback from the reviewers. Each paper is assigned a "shepherd" who is responsible for giving final approval.
My impression is that after a conditional acceptance, everyone both wants and expects the paper to be fully accepted: things felt a little more casual, a little less adversarial.
The reviewers had three main requests in the conditional acceptance:
- Present the rendering algorithm explicitly
- Add a figure that somehow shows rendering "work" density
- Do all of the line-by-line edits from the reviews
The request for a new figure was initially frustrating, because it was more work. After actually doing the work, I had to admit that it was a really good suggestion: Figures 9 and 10 ended up being some of my favorites, because they show off properties of the algorithm in an interesting way.

Other than that, the editing process was relatively straight-forward. The shepherd was enthusastic about replacing my previous results with the improved performance, and approved growing the paper from 9 to 10 pages to fit the extra text and figures.
I also used ispell
to spell-check the paper, since it understands LaTeX source.
On April 23th, I got the final sign-off from my paper's shepherd: I was approved to submit the final draft to the ACM upload system.
On April 24th, the in-person SIGGRAPH conference was cancelled.
May - Final submission
The show must go on! SIGGRAPH announced that it was going virtual, and my work on wrapping up the paper continued.
To submit the paper, I had to both upload a PDF to Linklings and send the full source of the paper to Stephen Spencer, presumably to make the canonical camera-ready paper.
This is also where the typesetting and layout is closely examined: I had to update my paper to put captions above tables, rather than below.
About 10 minutes before submitting the final version of the paper, I noticed that the names in the bibliography were mangled:

As it turns out, LaTeX / BibTeX don't play nicely with unicode:
instead of listing Hervé Brönnimann in the BibTeX file, I had to manually
escape the accents, i.e. Herv{\'{e}} Br{\"{o}}nnimann".
Once I noticed this, I found a handful of similar cases in my bibliography, which no one has caught in the whole review process!
I submitted the extremely final version of the paper on May 6th, built the landing page (with lovingly hand-crafted HTML/CSS), and emailed Ke-Sen Huang to be included in his annual list of papers.
Conclusion
Massively Parallel Rendering of Complex Closed-Form Implicit Surfaces is definitely not the coolest paper at SIGGRAPH this year.
(As the old joke goes, "What do you call the person who graduated last in their class at medical school?")
On the other hand, it's a very unusual accomplishment. In this year's crop of papers, only MPR and N-Dimensional Rigid Body Dynamics were written by authors outside of traditional academia and industry.
("Doctor")
It's hard to say if I'll ever do this again – I feel like I've checked it off my list – but it was definitely a unique and worthwhile experience.
Thanks for reading!
Matt Keeter
Somerville, MA
August 2020